

MongoDB 배포 형태: Replica Set와 Sharded Cluster
Replica Set
Replica Set은 고가용성(HA)과 데이터 복제를 위해 사용되는 구성입니다.
여러 각 노드는 독립적인 데이터베이스 인스턴스로서 역할을 수행합니다. 때문에 예를 들어 Primary 노드에 장애가 발생하더라도 Secondary 노드들은 여전히 서비스를 제공할 수 있습니다. 이는 시스템의 가용성을 높이고, 사용자가 중단 없이 서비스를 이용할 수 있도록 해줍니다.
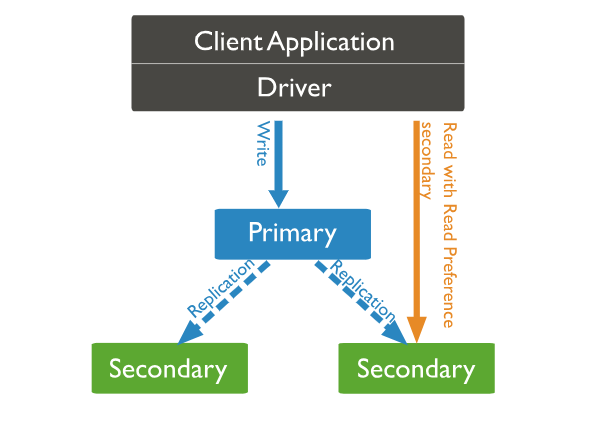
Primary 노드
- Replica Set 중 단 하나의 노드입니다.
- Primary 노드는 데이터 Read / Write 요청을 모두 처리할 수 있습니다.
- 다른 Secondary 노드들에게 데이터를 복제합니다.
Secondary 노드
- Replica Set에서 Primary 노드 외 나머지 노드입니다.
- Secondary 노드는 데이터 Read 요청만 처리할 수 있습니다.
- 복제를 통해 Primary와 동일한 데이터를 유지합니다.
- Primary 노드 장애 시 자동으로 Primary로 승격 될 수 있습니다.
💡 Replica Set 투표(Fail-Over)
Primary 노드에 장애가 발생했을 시 Primary로 승격할 Secondary 노드를 선택하기 위해 Replica Set의 노드들은 투표를 하여 Secondary 노드를 선출합니다. 방법으로는 2가지 유형이 있습니다.
1. P-S-S
Replica Set의 여러 노드들은 서로 살아있는지 주기적으로 확인(Heartbeat)을 해줍니다. 그리고 Primary 노드가 죽었다면 Secondary 노드들끼리 선출 알고리즘을 통해 Secondary 노드 중 하나가 선출되어 Primary로 승격됩니다. 여담으로 Replica Set을 설계할 때 Secondary 노드를 홀수 개 구축하라는 이유가 바로 투표때문입니다.
2. P-S-A
Arbiter라는 오직 투표만을 위한 노드를 두는 방법입니다. Arbiter는 데이터를 저장하지 않기 때문에 디스크 공간을 절약하면서 오직 투표 프로세스에만 참여합니다.
위 두 방식 중 P-S-S를 사용하길 더 권장합니다. 그 이유는 만약 Secondary 노드가 죽어버렸을 경우, P-S-S에서는 Primary 노드가 읽기 요청을 다른 Secondary 노드로 보내면 되기 때문에 부하가 가중되지 않습니다. 하지만 P-S-A에서는 Secondary가 죽었을 경우 Primary 노드가 읽기/쓰기 요청을 모두 처리해야하기 때문에 Primary 노드의 부하가 커질 수 있기 때문입니다.
💡 읽기 요청 분산 처리
Primary 노드는 Read / Write 요청을 모두 처리할 수 있지만, 읽기 요청 분산 처리하기 위해 Primary 노드에 Read 요청을 보내는 것이 아닌 Secondary 노드에 읽기 요청을 보낼 수 있습니다. 또한 여러 Secondary 노드가 동시에 읽기 작업을 처리할 수 있어 읽기 작업의 부하도 분산시킬 수 있습니다.
Secondary 노드로 읽기 요청을 보내기 위해선
'Read Preference Secondary' 설정
을 해주어야합니다. 만약 이 설정을 해주지 않으면 'Read' 요청은 Primary 노드로 가게됩니다.
💡Replica Set에서 데이터 복제하는 방법
Replica Set은 local database의 Oplog Collection을 통해 복제를 수행합니다.
Oplog에는 데이터 변경 작업에 대한 기록이 저장되어 있습니다. Oplog는 Primary 노드에서 발생한 쓰기 작업을 기록하여 이를 Secondary 노드들에게 복제함으로 데이터를 동기화합니다.
Oplog는 'local' 데이터베이스 내의 'oplog.rs' Collection에 저장됩니다.
Sharded Cluster
Sharded Cluster에서 'Cluster'는 여러 개의 서버 노드로 구성된 분산 데이터베이스 환경을 말합니다. 이때 각 서버는 'Shard'라 불리는 작은 단위로 데이터가 분할되어 저장되기 때문에 Sharded Cluster라 합니다.
Sharded Cluster는 수평적 확장을 통해 데이터를 분산 저장하고 검색할 수 있어, 대량의 데이터를 효과적으로 관리할 수 있습니다.
Sharded Cluster 내에 있는 각각의 Shard들은 모두 다른 데이터의 서브셋을 갖습니다. Sharded Cluster에 데이터가 A-Z까지 있다면 각각의 Shard는 Shard1: A-G / Shard2: H-O / Shard3: P-Z 이런식으로 데이터를 분산하여 갖고있습니다.
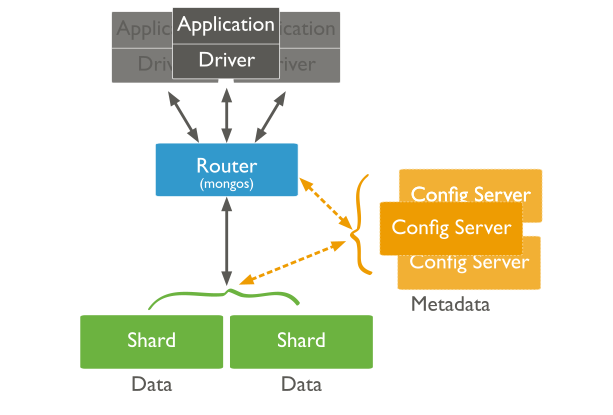
Shard:
클러스터 내의 부분으로, 각 Shard는 독립된 Replica Set입니다. DB의 큰 부분을 나눠 관리하여 분산처리에도 좋지만 각각의 Shard는 Replica Set이기 때문에 안정성과 가용성을 가집니다.
이때 Collection 단위로 Sharding이 가능합니다.
Shard Key:
데이터가 어떻게 분산되고 어떤 Shard에 저장할지를 결정하는 필드입니다.
Sharding을 위해선 Shard key를 선정해야하고 해당 필드에는 Index가 만들어져 있어야합니다.
예를 들면, 사용자 데이터를 저장한다면 사용자 아이디 등이 Shard Key가 될 수 있습니다.
mongos (Router):
클라이언트에서 발생한 쿼리를 Shard Key를 기반으로 적절한 Shard로 전달(라우팅)하고, 결과를 다시 종합해서 사용자에게 다시 반환하는 Router 역할을 합니다.
Config Server:
Sharded Cluster의 구성 정보를 저장하고 관리합니다. 어떤 데이터가 어느 Shard에 있는지, 어떤 Shard Key를 사용하는지 등도 알 수 있습니다.
Sharding 전략: Range Sharding VS Hashed Sharding

데이터를 분산하는 Sharding 전략으로 Range와 Hashed Sharding이 있습니다.
Range Sharding은 데이터의 범위를 미리 정하고, 그 범위 내의 데이터를 각 샤드에 할당하는 방법입니다. 들어오는 데이터의 범위가 고르게 분포되면 효과적인 Sharding이 가능하지만, 그렇지 않은 경우 불균형이 발생할 수 있습니다.
Hashed Sharding은 데이터의 해시 값을 사용하여 분산하는 전략입니다. 특정 필드의 값을 해시 함수에 넣어 나온 해시 값에 따라 데이터를 Sharding 합니다. 이를 통해 일관된 분산을 제공하며, 균형잡힌 분산을 기대할 수 있습니다.
(해시 함수의 특성상 특정 값에 대한 예측이 어렵습니다.)
배포 형태 선택: Replica Set vs Sharded Cluster
| 배포 형태 | 장점 | 단점 |
| Replica Set | 1. 높은 가용성 (장애 발생 시 해결이 쉽다.) 2. 운영이 쉽고, 서버 비용이 적음 |
Primary 노드는 하나이기 때문에 Read에 대한 분산은 가능하지만 Write에 대한 분산은 불가능 |
| Sharded Cluster | 1. Scale-Out 2. Write에 대한 분산이 가능 |
Replica Set의 장점들보다 상대적으로 성능이 덜함. |
가능하면 Replica Set으로 배포를 하고, 서비스의 요구 사항이 Replica Set으로 충족하지 못할 때 Sharded Cluster를 사용해주면 됩니다.